Data Collection in vRealize Automation is a process that keeps the vRA database in sync with endpoints such as vCenter Server. Most people reading this most likely already know how clunky this process is. Also, It’s not immediately obvious how this process can be automated from a vRO prospective. If you are performing any tasks against objects on your endpoints, such as day 2 actions that add or remove hard disks, networks, etc (and not using the OOTB reconfigure actions) then you almost certainly need to be able to programmatically invoke the data collection process to update all the information in vRA.
I have come across many different snippets of code that solved parts of the problem but were far from perfect and the code was ugly. I therefore decided to create something to make this process easy, whilst providing some additional quality of life features. So I present my Advanced Data Collection workflow for your pleasure.
You can find the package containing all the code here.
Page Contents
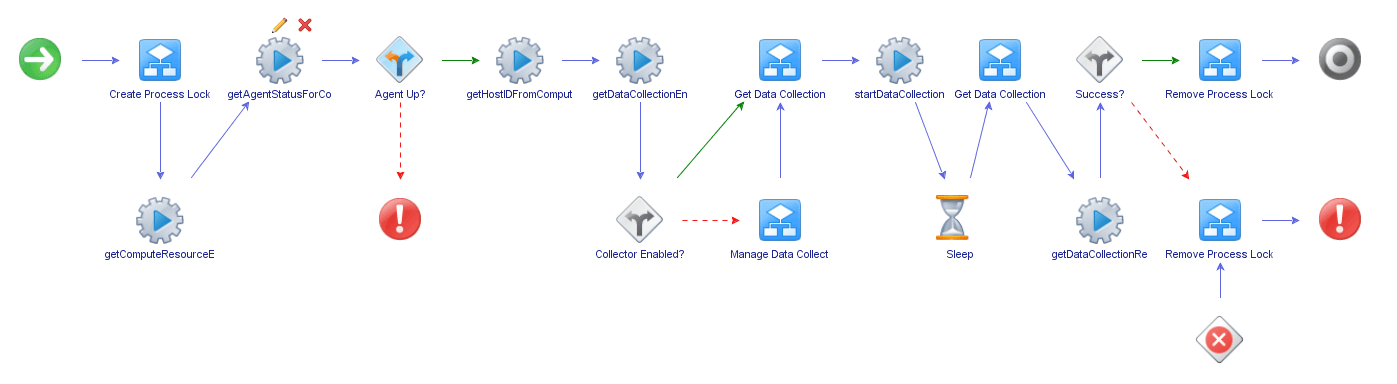
Data Collection Workflow Overview
When the workflow is run, the user is prompted to provide some inputs that they can easily select. I have set up the presentation for this workflow to present only data that is valid.
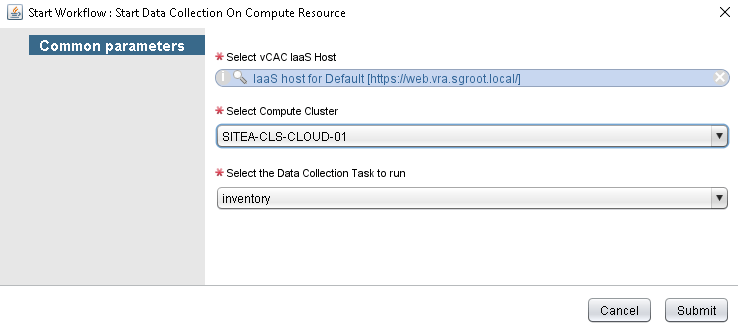
- Select vCAC IaaS Host allows you to browse the vRO inventory for any configured IaaS endpoints.
- Select Compute Cluster will automatically retrieve a list of clusters that have been configured in vRA (note that I have purposely set this to return clusters only and not standalone hosts).
- Select the Data Collection Task to run will provide a list of valid data collection types for the selected compute cluster.
When the workflow is executed, it will run through a series of steps:
- Creates a process lock so that no more than one data collection task is executed against a compute resource. I have also added code to allow the workflow to wait up to 30 minutes for any data collection task that has been invoked outside of this workflow.
- Checks that the Agent service associated with the compute resource is online. If the Agent is down then data collection would fail as vRA would not be able to communicate with the endpoint.
- Gets the uuid for the Compute Resource entity. The data collection entity associated with the compute resource shares the same uuid. There is no relationship between the compute resource entity and the data collection entities. Therefore, to locate the data collection entity, the compute resource uuid is required.
- Gets the current status of the data collector (is it Enabled or Disabled). If the data collector is disabled then it is automatically re-enabled.
- The data collection running status is then checked. This is where any data collection tasks invoked outside of the workflow is identified and handled. The workflow will hold for approximately 30 minutes for any currently running task to complete.
- The data collection task is started. This is achieved by setting the ‘LastCollectedTime’ property on the data collection entity to ‘null’.
- The data collection running status is then checked again. This will wait for the data collection task to complete.
- The last data collection run status is retrieved. This will output the data and time that the data collection task completed. An error will be displayed if this was not successful.
- Finally the process locks are removed (this will also occur if an exception is raised anywhere in the workflow).
Example Output
Here is an example output from a successful data collection run:
[] [I] [Workflow: Start Data Collection On Compute Resource] Trying to create lock: Attempt 1 of 180 [] [I] [Action: createLock] Creating lock on 'SITEB-CLS-CLOUD-01' for 'inventory' [] [I] [Action: createLock] Lock created for 'inventory' [] [I] [Action: getComputeResourceEntityByName] Retrieving vCAC Compute Resource entity with name: SITEB-CLS-CLOUD-01 [] [I] [Action: getVcacEntitiesByCustomFilter] Retrieving vCAC Entities for set: Hosts [] [I] [Action: getComputeResourceEntityByName] Found vCAC Compute Resource entity: SITEB-CLS-CLOUD-01 with ID: 9b049826-4934-49af-93c2-29793cbb8baf [] [I] [Action: getAgentStatusForComputeResourceEntity] Getting Agent status for compute resource 'SITEB-CLS-CLOUD-01' [] [I] [Action: getAgentStatusForComputeResourceEntity] Agent Status: true [] [I] [Action: getHostIDFromComputeResourceEntity] Retrieving Host ID for compute resource entity: SITEB-CLS-CLOUD-01 [] [I] [Action: getHostIDFromComputeResourceEntity] Found Host ID for compute resource entity:9b049826-4934-49af-93c2-29793cbb8baf [] [I] [Action: getDataCollectionEnabledStatus] Checking if 'inventory' data collection is enabled. [] [I] [Action: getDataCollectionEnabledStatus] Data collection 'inventory' enabled: true [] [I] [Action: getDataCollectionRunningStatus] inventory data collection task running: false [] [I] [Action: getComputeResourceEntityById] Retrieving vCAC Compute Resource entity with id: 9b049826-4934-49af-93c2-29793cbb8baf [] [I] [Action: getVcacEntitiyByUniqieId] Retrieving vCAC Entity for set: Hosts [] [I] [Action: getVcacEntitiyByUniqieId] Successfully retrieved vCAC entity. [] [I] [Action: getComputeResourceEntityById] Found vCAC Compute Resource 'SITEB-CLS-CLOUD-01' with ID '9b049826-4934-49af-93c2-29793cbb8baf' [] [I] [Action: startDataCollectionOnComputeResource] Starting 'inventory' data collection on compute resource 'SITEB-CLS-CLOUD-01' [] [I] [Action: startDataCollectionOnComputeResource] The 'inventory' data collection process on compute resource 'SITEB-CLS-CLOUD-01' has started. [] [I] [Action: getDataCollectionRunningStatus] inventory data collection task running: true [] [I] [Action: getDataCollectionRunningStatus] inventory data collection task running: true [] [I] [Action: getDataCollectionRunningStatus] inventory data collection task running: true [] [I] [Action: getDataCollectionRunningStatus] inventory data collection task running: false [] [I] [Action: getDataCollectionResultStatus] Retrieving the 'inventory' data collection result status. [] [I] [Action: getDataCollectionResultStatus] Data collection succeeded at: Fri Feb 08 2019 23:09:18 GMT-0000 (UTC) [] [I] [Action: removeLock] Removing lock on 'SITEB-CLS-CLOUD-01' for 'inventory' [] [I] [Action: removeLock] Lock removed for 'SITEB-CLS-CLOUD-01'
Limitations and things that could be improved
- If the Agent service is down then an idea might be to log into the server and restart the service.
Running Multiple Data Collection Tasks Concurrently
Now that I had a workflow to handle executing a single data collection task, I wanted to be able to run multiple data collections simultaneously. I wanted to try and avoid simply looping around this workflow for each compute resource that I wanted to run the data collection task on. This would have resulted in a synchronous execution of the workflow where the second task would only run when the first had completed, the third when the second had completed, and so on. This would have a cascading effect and would result in a long delay before the tasks completed. I therefore created a framework in which to run my workflows asynchronously.
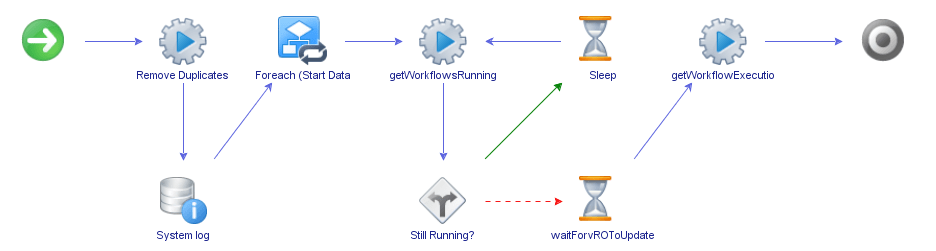
When the workflow is run, the user is again prompted to provide the same inputs as the previous workflow. The only difference is that you are able to select multiple compute resources to run data collection on.

This workflow will run through the following series of steps:
- Removes any duplicate compute resource names. Although, I would expect any list of compute resources that have been programmatically provided to be unique. It’s also useful if the same compute clusters were accidentally selected multiple times using the GUI.
- Loops through a helper workflow that asynchronously executes the data collection workflow for each compute resource provided. When the workflows are executed, this calling workflow does not wait for them to complete. Instead, the workflow execution tokens are retrieved so that the status can be checked later.
- Checks the running status of all the workflows. If at least one data collection workflow is running then the workflow will wait. A check is made every 10 seconds. If you had 10 data collection workflow tasks running then it will only take as long as the last workflow to finish. This speeds up the process considerably.
- Finally, when the process is complete, an execution report is provided.
Example Output
Here is an example output from a successful data collection run with the execution report included:
[] [I] Executing multiple data collection tasks. [] [I] [Action: getWorkflowsRunningStatus] Workflows are running... [...] [] [I] [Action: getWorkflowsRunningStatus] Workflows are running... [] [I] [Action: getWorkflowsRunningStatus] All workflows completed running tasks. [] [I] [Action: getWorkflowExecutionSummary] Workflow execution summary: [] [I] [Action: getWorkflowExecutionSummary] Completed workflows: 2 [] [I] [Action: getWorkflowExecutionSummary] Failed workflows: 0 [] [I] [Action: getWorkflowExecutionSummary] Cancelled workflows: 0 [] [I] [Action: getWorkflowExecutionSummary] Workflow execution details: [] [I] [Action: getWorkflowExecutionSummary] Workflows completed for the following items: - SITEA-CLS-CLOUD-01 - SITEB-CLS-CLOUD-01
The output details of the individual data collection tasks can be viewed on the main workflow that handles this.
Limitations and things that could be improved
- When selecting multiple compute resources, the data collection type is based on the first item in the list.
- It would be nice to limit the concurrent number of data collection workflows being executed (i.e. max 10 executions) to save CPU resources on the vRO appliance (not difficult so I will likely do this soon).
- It would be nice to see which workflows are still running in the logs. I have tried to do this but had problems. The code I was working on for this is still there but commented out, should anyone wish to take a look.
You could also apply the asynchronous approach to many other use cases (as I have). I will provide a follow up post on the specific details of this soon.
I hope this is helpful as it certainly was a life saver for me. If you have any comments or suggestions, find a bug or simply want some help, then please leave a comment or contact me via the Drift app.
Thats awesome Gavin, many thanks.
Thanks Paul!
Hello Gavin, great work! I tried to import this but it says it’s not a valid workflow….I suspect I’m running an older version of vRO (7.3) what version was this built on.